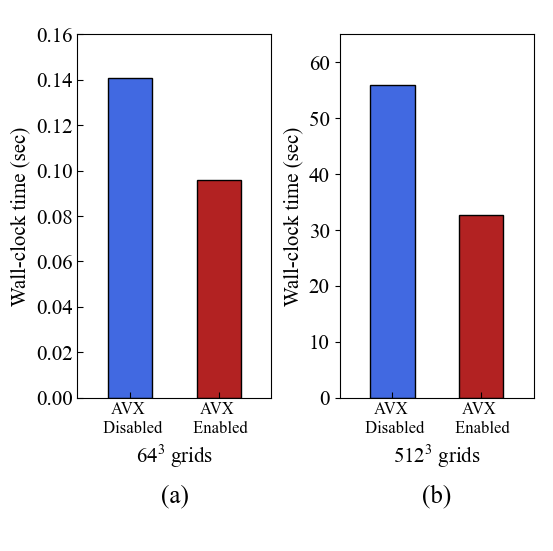
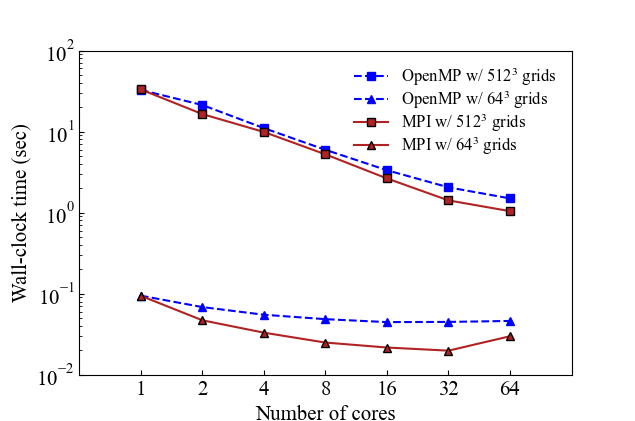
The scalability of parallelization, as exemplified by OpenMP and MPI, is optimal when the number of grids is high (\(512^3\)). However, when the grid number is low (\(64^3\)), the parallel performance is compromised.
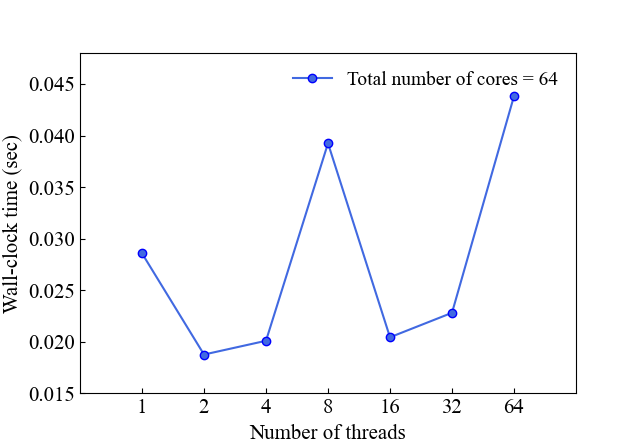
MPI w/ OpenMP hybrid parallelization
The parallel performance of the MPI with OpenMP hybrid approach is done in \(64^3\) grids and 64 total cores.
Hybrid parallelization represents an effective approach for appropriate OpenMP threads, and when the number of threads is set to two, it shows a 34% performance improvement compared to MPI parallelization.
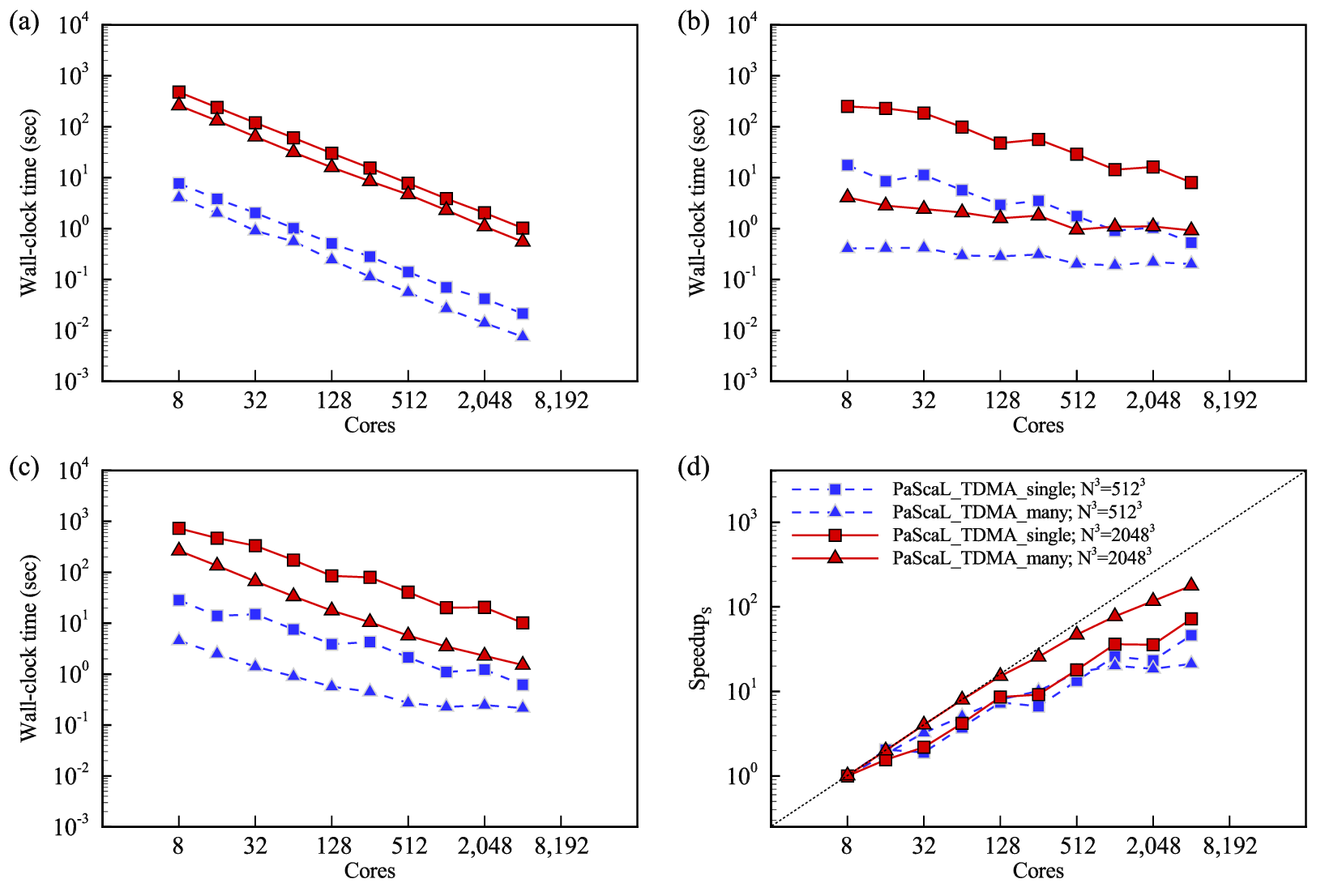
MPI: PaScaL_TDMA_single vs. PaScaL_TDMA_many
The strong scalability of PaScaL_TDMA_single and PaScaL_TDMA_many for the tridiagonal systems of the three-dimensional array.
The results for the fixed grid size of \(512^3\) and \(2,048^3\) are plotted in blue dashed and red solid lines, respectively.
The measured performance of PaScaL_TDMA_single and PaScaL_TDMA_many are represented as square and triangular symbols, respectively.
(a) Computation time, (b) communication time, (c) total execution time, and (d) speedup curve starting from 8 cores.
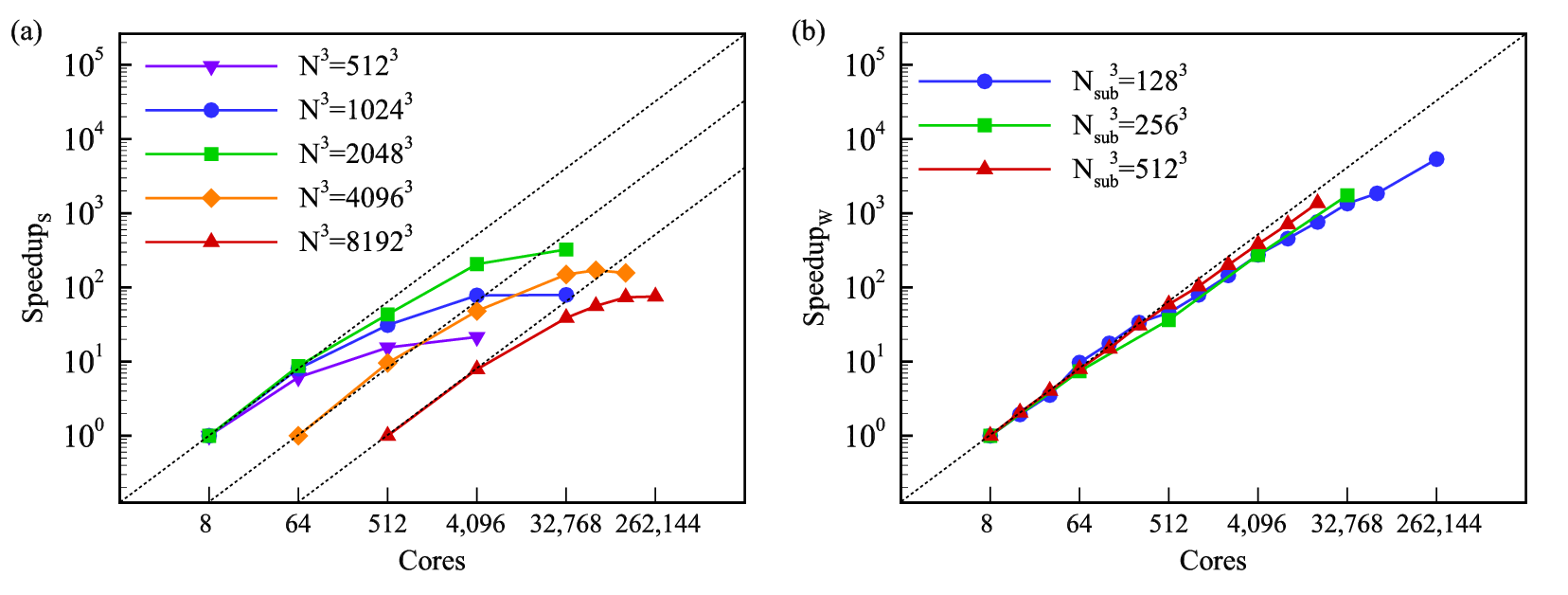
The scalability of PaScaL_TDMA_many for solving the three-dimensional heat equation. The dashed lines represent the ideal speedup. (a) Strong scalability and (b) weak scalability.
The analysis was based on the total execution time, including not only the time for solving the tridiagonal systems but also the processing time for constructing the coefficient matrices and right-hand sides of the tridiagonal systems.
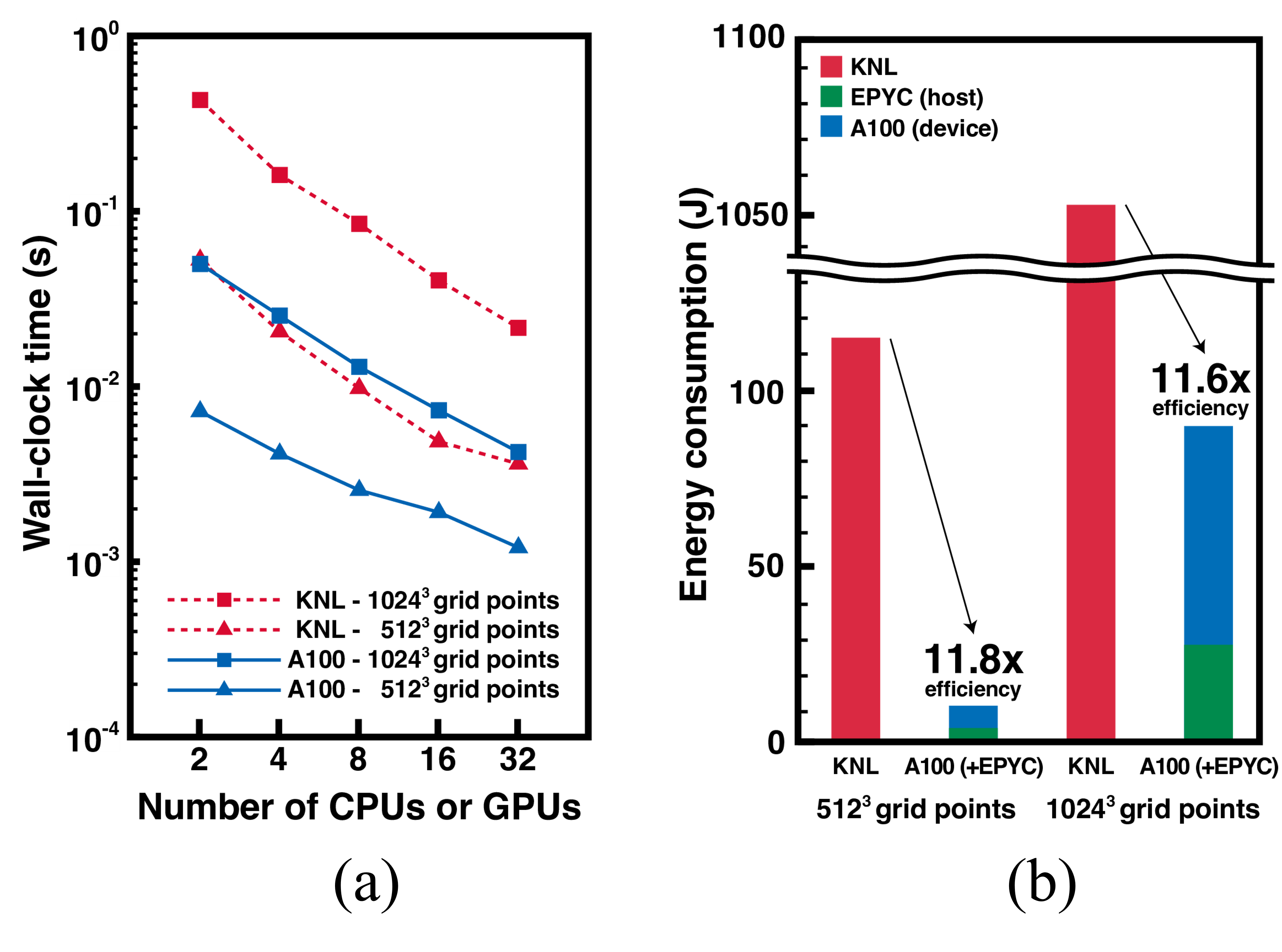
(a) Strong scalability cureves with wall-clock time results as a fuction of the number of CPUs/GPUs and (b) energy consumption results obtained with two KNL CPUs and two A100 GPUs, respectivley.
[CPU Environment]
All the computations were executed on the Nurion manycore cluster at the Korea Institute of Science and Technology Information (KISTI). The Nurion consists of 8,305 Cray CS500 nodes interconnected by the Intel Omni-Path Architecture. Each node has a 68-Core Intel Xeon Phi 7250 processor with 16GB of high bandwidth on a chip and 96 GB of main memory. Each simulation is repeated for 10 time steps to average any small fluctuations in the execution time. An executable program was built using an Intel compiler (version 19.0.1.144) with the flags of full optimization (-O3) and automatic vectorization according to the hardware architecute (-xMIC-AVX512).
This environment proposed by Kim et al. (2021)
GPU
Note
[GPU Environment]
We evaluated the computational performance and energy efficiency of the GPU implementation of PaScaL_TDMA 2.0 on the NEURON cluster at the Korea Institute of Science and Technology Information (KISTI). The cluster consisted of two AMD EPYC 7543 processors (hosts) and eight NVLnk-connected NVIDIA A100 GPUs (devices) per compute node. The results were compared with those obtained on the NURION cluster at KISTI, which features an Intel Xeon Phi 7750 Knight Landing (KNL) processor per compute node. Intel OneAPI 22.2 and NVIDIA HPC SDK 22.7 were used to compile PaScaL_TDMA 2.0 on the NURION and NEURON clusters, respectively.
This environment proposed by Yang et al. (2023)